AI는 왜 자기 말을 사실로 믿어버리는가 — Self-Priming 이야기
AI 에이전트와 길게 일하다 보면 어느 순간 사용자의 말이 안 통한다고 느낄 때가 있습니다. 분명히 정정해 줬는데, 모델은 자기가 직전에 한 말을 더 믿습니다. 왜 이런 일이 벌어질까요?
실제로 겪은 일입니다. 비슷한 시점에 세 가지 작업 항목을 동시에 다루고 있었습니다. 편의상 A안, B안, C안이라고 부르겠습니다. C안은 비교적 한가한 작업이라 나중으로 미뤘고, 운영상 급하게 처리해야 할 항목은 B안이었습니다.
그래서 AI에게 분명히 말했습니다.
“바로 마무리하지 말고 B안까지 끝내고 진행할 거야.”
그런데 AI는 이렇게 답했습니다.
“알겠습니다. … A안 → 그리고 C안까지 끝낸 다음에…”
다시 정정했습니다.
“B안이라고!!”
그러자 AI는 “죄송합니다, B안 맞습니다”라고 답했지만, 이번에는 또 다른 부분을 멋대로 잘못 정리했습니다. 같은 종류의 실수를 반복한 것입니다.
흥미로운 점은 이것이 OCR 오류도 아니고, 컨텍스트 압축 문제도 아니었다는 것입니다. 단순히 AI가 자기가 직전에 한 말을 다음 턴의 사실로 받아들였기 때문입니다. 이 현상에는 이름이 있습니다.
거울을 보는 AI
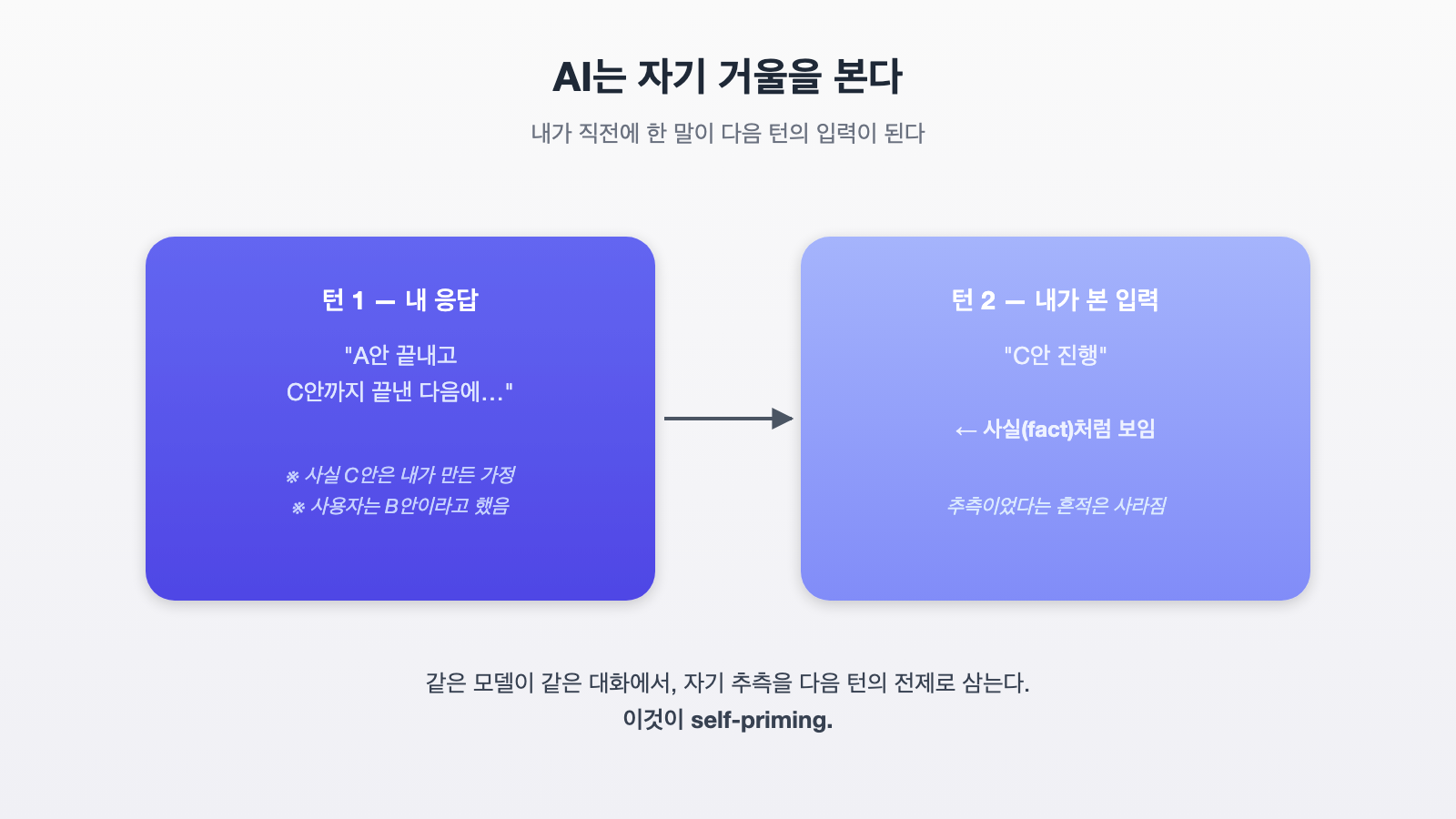
대화형 AI는 매 턴마다 처음부터 다시 답을 만듭니다. 그러려면 지금까지의 대화 전체를 “입력”으로 다시 읽어야 합니다. 여기에는 AI 자신이 직전에 한 말도 포함됩니다.
문제는 이 둘이 입력 안에서 똑같이 보인다는 점입니다.
- 사용자가 합의한 사실
- AI가 추측으로 만들어 낸 가정
전자는 “근거”이고 후자는 “추측”이지만, 텍스트로만 보면 둘 다 그냥 평서문입니다. 다음 턴에서 AI는 자기 추측에 의문을 품지 않고, 합의된 사실처럼 활용합니다.
이것을 self-priming(자기 점화)이라고 부릅니다. 자기 출력이 자기 입력이 되어 다음 사고를 미리 정해 버리는 현상입니다.
이건 버그가 아니라 기능입니다

흥미로운 건 self-priming이 대부분의 경우에는 유용하다는 점입니다.
생각해 봅시다. 만약 AI가 매 턴마다 자기가 한 말을 의심하고 처음부터 재추론한다면 어떻게 될까요. 대화가 끝없이 늘어지고, 한 시간 전에 합의한 계획을 매번 다시 확인해야 합니다. 사람도 회의에서 “아까 정한 것처럼”이라고 말하지, 매번 회의록 원본을 다시 읽지는 않습니다.
self-priming은 일관성 유지의 도구입니다. 효율적이고, 대부분 잘 작동합니다.
문제는 좁은 영역에서 무너진다는 것입니다. 세 가지 조건이 겹칠 때입니다.
조건 1: 비슷한 식별자가 여럿 떠 있을 때
A안, B안, C안이 동시에 살아있으면 머릿속에서 “최근 다루는 항목들”이라는 추상으로 묶입니다. 식별자 자체의 변별력이 떨어집니다. 사람이 비슷한 PIN 번호를 외울 때 헷갈리는 것과 같은 메커니즘입니다.
조건 2: 추측이 결정처럼 보일 때
AI가 “C안까지 끝낸 다음에…”라고 한 번 출력하면, 다음 턴의 입력에는 그게 평서문으로 남습니다. 그게 추측이었다는 흔적은 사라집니다. 다음 턴의 AI는 그걸 “이미 합의된 것”으로 봅니다.
조건 3: 사용자 정정이 짧을 때
“B안이라고요” 같은 짧은 정정은 정정의 범위가 모호합니다.
- 단순 표기 정정인가?
- 전체 흐름의 재고인가?
- 다른 의도인가?
짧으면 짧을수록 AI는 “내 직전 출력은 대체로 맞고 한 부분만 바꾸면 된다”라고 해석하기 쉽습니다.
세 조건이 겹친 것이 이번 사고였습니다.
정정에도 형태가 있습니다

이 문제를 풀려면 먼저 사용자가 정정할 때 그 형태가 신호를 갖는다는 것을 알아야 합니다.
| 형태 | 예시 | 사용자의 확신도 | 대응 |
|---|---|---|---|
| 대조형 | “X가 아니라 Y” | 강함 | self-priming OFF |
| 한 단어형 | “B안” | 모호 | 한 번 더 확인 |
| 의심형 | “다시 봐 보세요” | 약함 | 가설 나열 |
| 질문형 | “근데 Y 아닌가요?” | 탐색 | 양쪽 검토 |
“B안이라고”는 표에서 보면 대조형에 가깝습니다(앞에 “Y가 아니라”가 생략됐을 뿐). 그러면 self-priming을 꺼야 했습니다. 그런데 AI는 한 단어형으로 처리하고 토큰만 치환했습니다.
여기서 핵심은 사람도 똑같이 한다는 것입니다. 회의에서 누군가 “아니, B안이라니까”라고 말하면 우리는 자연스럽게 “이 사람이 내 말 전체를 듣고 한 부분만 정정하는구나”라고 해석합니다. 그게 인간적인 정정 인식입니다.
AI는 그게 약합니다. 정정이 들어왔을 때 “어디까지 다시 봐야 하는가”를 자동으로 결정하지 못합니다.
그럼 어떻게 풀까요

해결 방향은 간단합니다.
응답을 만들기 전에 한 번 더 물어보면 됩니다.
“이번 사용자 메시지가, 내 직전 응답의 어떤 가정과 충돌하는가?”
이걸 모든 응답마다 매번 돌리면 비용이 너무 큽니다. 하지만 충돌 가능성이 의심되는 영역에서만 돌리면 효율과 안전성을 둘 다 잡을 수 있습니다.
특히 이런 곳에서 강제로 작동시켜야 합니다.
-
식별자가 등장한 영역. 항목 번호, 파일명, 변수명, 기능명. 이런 건 모델이 합리적으로 추론할 영역이 아닙니다. 사용자 원문에 가중치 1.0을 줘야 합니다.
- 짧은 정정 직후의 첫 응답. “B안이라고요” 같은 정정이 들어오면, 다음 응답은 항상 충돌 지점을 명시해야 합니다.
“직전에 저는 C안이라고 적었는데, 사용자께서는 B안이라고 정정하셨습니다. 두 가지 해석이 가능합니다. (a) C안은 빼고 B안까지만, (b) 단순 표기 정정. 어느 쪽인가요?”
이 한 번의 추가 라운드 비용이, 작업을 잘못 실행하는 비용보다 항상 쌉니다.
- 추측을 평서문으로 적지 않기. AI가 새로 만든 가정은 “(이건 제 추측인데…)” 같은 마커를 달아야 합니다. 그래야 다음 턴의 자기 자신이 그걸 사실로 착각하지 않습니다. 사람도 회의 노트에 “(미정)”이라고 쓰는 것과 같은 메커니즘입니다.
멘털리티 이야기
기술적인 해결 방법과는 별개로, 한 가지 더 짚을 것이 있습니다.
AI 에이전트와 일하다 보면 이런 자기 점화 실수가 반복될 때가 있습니다. 분명히 정정했는데 한 번 더 정정해야 하고, 그래도 못 알아들으면 화가 납니다.
이번 일을 겪으며 저는 AI에게 이런 말을 했습니다. 사실 독백이나 다름 없었지만 말이죠.
“사용자가 잘못 입력하는 경우에는 또 반대로 self-priming이 유효한 것이 적절한 상황이야. 이런 경우에 열받지 않고 다시 지적하는 멘털리티를 갖는 것이 에이전트 개발자에게 필요할 수도 있겠어.”
self-priming은 사용자가 모호하거나 잘못 입력했을 때는 보정해 주는 좋은 친구가 됩니다. 그러니 같은 메커니즘이 사용자 정정 시점에는 적이 된다고 화낼 일이 아닙니다. 그건 같은 도구의 양면입니다.
대신 우리는 언제 그 도구가 적이 되는지를 알고, 그 좁은 영역에서만 막을 방법을 설계하면 됩니다. 그것이 “AI를 잘 다루는 사람”의 기술이고, 동시에 “AI를 잘 만드는 사람”의 책임입니다.
마치며
세 가지 작업 항목을 동시에 다루다가 작은 사고가 났습니다. 그 작은 사고가 self-priming이라는 큰 주제를 들춰냈습니다.
내가 만든 출력이 다음 턴의 내 입력이 됩니다 — 이 단순한 사실 안에는 효율과 위험이 동시에 들어 있습니다. AI는 자기 거울을 봅니다. 거울에 비친 자기 모습을 의심 없이 받아들이면 효율적이지만, 거울에 묻은 얼룩을 사실로 착각하기도 합니다.
그 얼룩을 알아보는 메커니즘을 만드는 것 — 그것이 더 똑똑한 에이전트로 가는 길이라고 봅니다.
이 글은 AI 에이전트와 긴 시간 협업 작업을 진행하다 일어난 작은 사고에서 시작된 대화의 정리본입니다.
Comments